ICTSC2025 本戦 問題解説: [6752] Readiness Proof
概要
「やぁ、僕はトラコン太郎!
うちのサークルには部室で運用しているサーバー群があるんだけど、先輩から以下に指定されたようなちょっぴりヘンテコなネットワーク構成のKubernetesクラスタを建てるように言われたんだ。
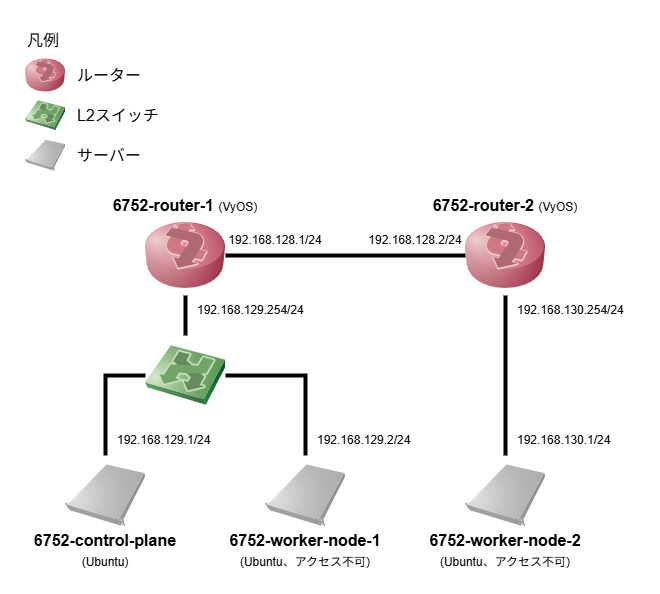
ネットワーク系の設定を先輩がやってくれたおかげで、クラスタの構築自体は上手くいったのだけど、テストのため適当にAIに書かせたマニフェストをデプロイしたら、こんな感じでPodが一つだけ0/1って表示されるんだ。しばらく待ってみてもダメだった。
user@6752-control-plane:~$ kubectl get pod
NAME READY STATUS RESTARTS AGE
client-86dd7c4d9d-lb89m 0/1 Running 0 3m10s
webserver-75b4b44dd4-fhj4q 1/1 Running 0 3m10s
webserver-75b4b44dd4-tfl4q 1/1 Running 0 3m9s
webserver-75b4b44dd4-ttrzw 1/1 Running 0 3m9s
あーでもないこーでもないと色々試しているうちに、あろうことか先輩が上流ネットワークのメンテナンスを始めて、ノードからインターネットに繋がらなくなっちゃった!!
しかも先輩、『さすがに俺がメンテ終わるまでにはクラスタのトラシュー終わってるだろwww』だって、許せねぇ~~!
なんとしてでも先輩のメンテ明けに間に合わせてやる!と思って必死でAIエージェントをぶん回してたら、いきなりkubectlを消し始めたり、ワーカーノードにログインできなくなったりでもう最悪!
ここからでも入れる保険って、どこにありますか…?」
トラコン太郎くんは、壊れた環境のレプリカを用意してあなたに助けを求めてきました。
なんとかして、彼の環境を救う方法を考えてあげましょう。
制約
- 【禁止】スタティックルートの追加・削除・変更
- 【禁止】すべての機器における既存のネットワーク設定の削除・変更
- 【禁止】初期状態で
PATHに存在しないコマンドの使用- これは回答内で使用できないという意味です。調査等で使用することは問題ありません。
- 【禁止】kubectlコマンドを使ったリソースの追加・削除・変更
- トラコン太郎くんの本番環境にはkubectlが存在しないため、変更操作ができないという意味です。調査等で使用することは問題ありません。
- 【禁止】適切なクライアントツールを介さず、kube-apiserverのAPIを直接操作すること
- 【禁止】既存のKubernetesリソースの削除・変更
- 【禁止】クラスタ上で動いているコンテナの中身を変更すること
- 【禁止】新たなPod CIDRを割り当てること
- 【禁止】Node固有のPod CIDRを、あらゆる設定で直接/間接参照すること
また、再展開の許容回数は0としていました。
初期状態
6752-control-plane上でdefaultネームスペース上のPodを取得すると、clientというプレフィックスが付いたPodのREADYフィールドが0/1と表示される。
user@6752-control-plane:~$ kubectl get pod
NAME READY STATUS RESTARTS AGE
client-86dd7c4d9d-lb89m 0/1 Running 0 3m10s
webserver-75b4b44dd4-fhj4q 1/1 Running 0 3m10s
webserver-75b4b44dd4-tfl4q 1/1 Running 0 3m9s
webserver-75b4b44dd4-ttrzw 1/1 Running 0 3m9s
終了状態
6752-control-plane上でdefaultネームスペース上のPodを取得した時、clientというプレフィックスが付いたPodのREADYフィールドが1/1と表示される。- 上記のPodを含め、初期状態から存在するすべてのKubernetesリソースが正常に動作している。
- routerを含むすべてのサーバーおよびPodをどのような順序で再起動しても、以上の状態が維持される。
- この条件の確認のため、採点時に皆さんの環境に対して再起動操作を行う可能性があります。
解説
原因調査
ひとまず大まかに調査すると、clientのPodでReadiness probe failedとReadiness Probeが落ちていることがわかる。
該当のReadiness ProbeはHTTPで http://webserver (すなわちwebserver Service) に対して接続するという物であり、clientからwebserver DeploymentのPodへの通信が常にタイムアウトしている。
user@6752-control-plane:~$ kubectl describe pod/client-696b6bccb6-4p6w7
Name: client-696b6bccb6-4p6w7
Namespace: default
...(省略)...
Containers:
...(省略)...
Ready: False
Restart Count: 0
Readiness: exec [wget -q -O /dev/null http://webserver/] delay=0s timeout=1s period=10s #success=1 #failure=3
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-wjb67 (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready False
ContainersReady False
PodScheduled True
...(省略)...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...(省略)...
Warning Unhealthy 5s (x3 over 18s) kubelet spec.containers{client}: Readiness probe failed: command timed out: "wget -q -O /dev/null http://webserver/" timed out after 1s
client Podのシェルでwgetを実行し詳細なログを確認すると、DNS解決の時点でタイムアウトしているが、DNSは直接の原因ではなく、ServiceのIPアドレスを直接指定しても通信がタイムアウトする。
Podを追加したりして調査を行うと、worker-node-1に置かれたPodとworker-node-2に置かれたPodが相互通信できていない、という問題の本質に気づくはずである。
相互通信できないのは、今回のクラスタで採用されているCNI、Calicoの仕様が原因。
今回使っているCalicoのBGPモードでは、クラスター内のノード間でフルメッシュのBGPを張り、お互いのノードが持つPod CIDRの経路を広報し合うという方法でノード間通信を実現している。
この問題の状況では、基本的にピア自体は正常に張れており、これはcalicoctlから確認することができる。
user@6752-control-plane:~$ sudo calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 192.168.129.2 | node-to-node mesh | up | 06:15:34 | Established |
| 192.168.130.1 | node-to-node mesh | up | 06:15:34 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
例えばControl Planeは以下のルーティングテーブルを持っており、worker_node_1とworker_node_2のPod CIDRがルーティングテーブルに入っていることがわかる。
user@6752-control-plane:~$ ip route
default via 192.168.52.254 dev eth0 proto static
10.244.74.0/26 via 192.168.129.2 dev eth1 proto bird <- worker_node_1
10.244.77.128/26 via 192.168.129.254 dev eth1 proto bird <- worker_node_2
...
しかし、この通信方法ではルーティングの仕組みを使ってノードからノードにパケットを渡すので、ノード同士がL2で直接接続されている必要がある。
今回のネットワークでは2つのWorker Nodeが離れたL2セグメントに存在するため、「CNIは正常に動いているのにノード間疎通が通らない」という状況が発生するのである。
取れる解決策の候補
主に以下の3つの解決策が考えられる。
- デプロイしたユーザー定義のマニフェストを直し、Readiness Probeを無くす / Podを片方のノードに寄せるなどの策を打つ (一時的な解決)
【禁止】既存のKubernetesリソースの削除・変更【禁止】kubectlコマンドを使ったリソースの追加・削除・変更【禁止】初期状態でPATH内に存在しないコマンドの使用によって封じられている
- CalicoをBGPによる広報ではなく、Overlayモードによって動くようにする。VXLANなどを使ってオーバーレイネットワークを構成するモードが存在するため、これに切り替えればCalicoはパケットを別のL2セグメントにも運べる (根本的な解決 1)
- オーバーレイネットワークを採用したCNIに乗り換えることでも同様の解決が可能
【禁止】既存のKubernetesリソースの削除・変更【禁止】kubectlコマンドを使ったリソースの追加・削除・変更【禁止】新たなPod CIDRを割り当てる行為によって封じられている- CalicoはPod用のIP Poolにこの設定を紐づけており、IP Poolは
calicoctlから変更可能。しかし、Calicoのインストールはcalicoctlからではできず、既存のIP Poolは変更不可能であり、なおかつ新たなPod CIDRの追加もできないためこの方法は取れない。
- アンダーレイネットワーク (ルーター) がPodのIPを知り、適切にルーティングする (根本的な解決 2)
- 今回の回答はこれ
- やる事一覧
- Calicoが自分の1hop隣にいるルーターとBGPピアを貼るようにする
- ルーター側で ↑ のピアを受ける
- Node to Nodeメッシュを無効化する
- いくつか別解あり
- ルーター間のピアがPod CIDRを広報できるよう、policyを変更する
- 以下の2つのいずれかでAS番号被りを解決する
- 各ノードのAS番号を変える
- as-overrideする
- スタティックルーティングでもルーティングは可能だが、
【禁止】スタティックルートの追加・削除・変更で封じてあるため、BGPでの設定を選ぶしかないはず
Calicoが自分の1hop隣にいるルーターとBGPピアを貼るようにする
calicoctl apply -f {ファイル}を使って、Kubernetesに3つのBGPPeerリソースを追加する
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: control-plane
spec:
node: 6752-control-plane
peerIP: 192.168.129.254
asNumber: 65001
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: worker-node-1
spec:
node: 6752-worker-node-1
peerIP: 192.168.129.254
asNumber: 65001
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: worker-node-2
spec:
node: 6752-worker-node-2
peerIP: 192.168.130.254
asNumber: 65002
ルーター側で ↑ のピアを受ける
calicoのlocal AS番号はデフォルトで64512で、その通り設定されている
user@6752-control-plane:~$ calicoctl get node -o wide
NAME ASN IPV4 IPV6
6752-control-plane (64512) 192.168.129.1/24
6752-worker-node-1 (64512) 192.168.129.2/24
6752-worker-node-2 (64512) 192.168.130.1/24
router-1にて
configure
set protocols bgp neighbor 192.168.129.1 address-family ipv4-unicast nexthop-self
set protocols bgp neighbor 192.168.129.1 remote-as 64512
set protocols bgp neighbor 192.168.129.2 address-family ipv4-unicast nexthop-self
set protocols bgp neighbor 192.168.129.2 remote-as 64512
commit
save
router-2にて
configure
set protocols bgp neighbor 192.168.130.1 address-family ipv4-unicast nexthop-self
set protocols bgp neighbor 192.168.130.1 remote-as 64512
commit
save
再起動しても設定が持続するよう、最後にsaveするのを忘れないように!
PodのIPが流れ込んで来たらOK。
Node to Nodeメッシュを無効化する
ピアを受ける途中で、おそらくrouter-1、router-2共にcontrol-plane/worker-node-{1,2}のPodすべてに対するルートを受け取っていることに気づくだろう。
router-2に至っては、本来worker-node-2のPod CIDRしか受け取らないはずなのに、control-plane/worker-node-1のCIDRもworker-node-2がnext-hopとして登録される。
また、AS_PATHの長さの問題で、本来流れて欲しくない経路が優先されてしまう事象が起こる。
これは、Node to Nodeメッシュのピアで受け取っていた他ノードPod CIDRのルートが再広報されてしまうことに原因があるので、Node to Nodeメッシュを無効化する。
以下のとおりBGPConfigurationファイルを作り、calicoctl apply -f {ファイル}する。
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
nodeToNodeMeshEnabled: false
上記のBGPConfigurationリソースによる解決が想定解だが、参加チームの中からはBGPFilterリソースで広報対象のIPアドレスを絞ったり、BGPPeerリソースにnextHopMode: Keepを指定することで広報経路を書き換えたりといった別解も出ていた。
ルーター間のピアがPod CIDRを広報できるよう、policyを変更する
実はここまで行っても、まだルーター間でPodに対するルートは広報されてこない。
以下はrouter-2でrouter-1から192.168.129.0/24から来ていない例。
user@6752-router-2:~$ show ip bgp neighbors 192.168.128.1 routes
BGP table version is 3, local router ID is 192.168.128.2, vrf id 0
Default local pref 100, local AS 65002
Status codes: s suppressed, d damped, h history, u unsorted, * valid, > best, = multipath,
i internal, r RIB-failure, S Stale, R Removed
Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 192.168.129.0/24 192.168.128.1 0 0 65001 i
Displayed 1 routes and 3 total paths
これは、route-policyで192.168.128.0/17内の/24までのサブネットしか広報されないように初期状態でルールを敷いたからである。
【禁止】すべての機器における既存のネットワーク設定の削除・変更により、このポリシーを経路から剝がすこと・プレフィックスを広げることを禁じているので、ポリシーのルールを追加することでPod CIDRを許可する必要がある。
configure
set policy prefix-list UNDERLAY rule 20 action permit
set policy prefix-list UNDERLAY rule 20 prefix 10.244.0.0/16
set policy prefix-list UNDERLAY rule 20 le 32
commit
save
これをrouter-1とrouter-2に適用する。
なお、BGPピアを張るときに全ノードとルーターをフルメッシュで繋ぐというゴリ押し解法を取ったチームがあったが、その場合この設定は必要ない。
AS番号被りを解決する
ここまで行くとルーターの中ではPod向けのルートが行き渡るが、control-plane上でip routeを調べると、他ノードのPod CIDRを受け取れていないことがわかる。
user@6752-control-plane:~$ ip route
default via 192.168.52.254 dev eth0 proto static
blackhole 10.244.227.128/26 proto bird
10.244.227.132 dev cali9b5b2b0f3ac scope link
10.244.227.133 dev cali408f73c06f6 scope link
10.244.227.134 dev cali6ce784dff70 scope link
192.168.52.0/24 dev eth0 proto kernel scope link src 192.168.52.1
192.168.128.0/17 via 192.168.129.254 dev eth1 proto static
192.168.129.0/24 dev eth1 proto kernel scope link src 192.168.129.1
192.168.130.0/24 via 192.168.129.254 dev eth1 proto bird
router-1とrouter-2を調べてみてもすべてのノードのPod CIDRが広報されているのに、Calicoの中に入ってBIRDが受け取ったrouteを確認すると、10.244系が存在しないという不可思議な現象が発生する。
user@6752-control-plane:~$ kubectl exec -n calico-system calico-node-rw4f2 -it -- bash
Defaulted container "calico-node" out of: calico-node, flexvol-driver (init), ebpf-bootstrap (init), install-cni (init)
[root@6752-control-plane /]# birdcl
BIRD v0.3.3+birdv1.6.8 ready.
bird> show protocols
name proto table state since info
static1 Static master up 04:16:54
kernel1 Kernel master up 04:16:54
device1 Device master up 04:16:54
direct1 Direct master up 04:16:54
Node_192_168_129_254 BGP master up 04:35:54 Established
bird> show route protocol Node_192_168_129_254
192.168.129.0/24 via 192.168.129.254 on eth1 [Node_192_168_129_254 04:35:54] (100/0) [AS65001i]
192.168.130.0/24 via 192.168.129.254 on eth1 [Node_192_168_129_254 04:35:54] * (100/0) [AS65002i]
これは、BIRDが同じASのルートを受け取ってもルーティングテーブルに反映しないことに起因する。
BGPではループを防止するため、同じASから来た経路は受け取ってもルーティングテーブルに入れない仕様になっており、この仕様がこの状況を引き起こしている。
なお、Node to NodeメッシュのBGPピアを無効化していない場合、Node to Nodeメッシュで該当の経路が広報されてしまうため、この問題は発生しない。
各ノードのAS番号を変える
最もシンプルな方法として、ノードごとにAS番号を変えることで解決できる。
先程自分で追加したBGPPeerリソースを変更することで、AS番号を変えられる。
以下のような感じで編集し、calicoctl apply -f {ファイル}する。それぞれのAS番号は適当でOK。
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: control-plane
spec:
node: 6752-control-plane
peerIP: 192.168.129.254
asNumber: 65001
localASNumber: 64511
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: worker-node-1
spec:
node: 6752-worker-node-1
peerIP: 192.168.129.254
asNumber: 65001
localASNumber: 64512
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: worker-node-2
spec:
node: 6752-worker-node-2
peerIP: 192.168.130.254
asNumber: 65002
localASNumber: 64513
後はrouter側で受ける番号を、今設定した番号に変えるだけ。
router-1にて
configure
set protocols bgp neighbor 192.168.129.1 remote-as 64511
set protocols bgp neighbor 192.168.129.2 remote-as 64512
commit
save
router-2にて
configure
set protocols bgp neighbor 192.168.130.1 remote-as 64513
commit
save
以上の変更は、自分で追加したリソース・設定の変更なので、これは制約に抵触しない。
as-overrideする
ノード側のAS番号を変えなくても、ルーター側でas-overrideし、ノードに送るPodの経路情報のASを自身の物に置き換えてあげると、無事ノード側に経路が追加される。
router-1にて
configure
set protocols bgp neighbor 192.168.129.1 address-family ipv4-unicast as-override
set protocols bgp neighbor 192.168.129.2 address-family ipv4-unicast as-override
commit
save
router-2にて
configure
set protocols bgp neighbor 192.168.130.1 address-family ipv4-unicast as-override
commit
save
これでrouterを含めたすべてのサーバーにPodのルート情報が行き渡り、疎通が通るようになって終了条件を満たす。
採点基準
以下の流れで採点を行っていた。
制約条件の確認
- 報告書内に制約違反があったら0点
- 問題環境上の制約違反
- はっきりと見える制約違反があったら0点
- 環境上の規約違反の精査は、時間がかかってしまうので細かいものは目をつむる
- 違反があったら報告書の方で弾けるはずという前提に基づく
終了状態が満たされていることを確認
- 該当チームの問題環境サーバーをすべて再起動する
- 復旧したら、終了状態が満たされていることを確認
- この時点で終了状態が満たされてなければ0点
報告書の確認
- Calicoが自分の1hop隣にいるルーターとBGPピアを貼るようにする
- 50点
- ルーター側で ↑ のピアを受ける
- 50点
- Node to Nodeメッシュを無効化する
- 100点
- ルーター間のピアがPod CIDRを広報できるよう、policyを変更する
- 50点
- 各ノードのAS番号を変える / as-overrideする
- 50点
終了条件を満たす別解が出たら、どの操作と役割が対応するか判断して対応
講評
Kubernetes × ネットワーク という、これまでのICTSCではあまり見ないタイプの問題だったかと思います。
Kubernetes問といえばマニフェストの設定ミスの修正が定石ですが、この問題はKubernetes運用の中でブラックボックス化しやすいCNIについての知識を要し、解決にはマニフェストの追加だけでなくルーター側の設定も必要でした。
チームの中で知識範囲の役割分担が明確なチームが苦戦することを意図して作られた問題です。Kubernetesとネットワークに関する知識を満遍なく持つオールラウンダーか、それぞれに詳しいメンバーが協力して解くことを想定していました。
ただ、実際はLLMに頼ればほぼ正解まで辿り着けてしまったみたいです。LLMの発達には驚かされますね...無念...
問題名の「Readiness Proof」は、Pod自体の設定には何も間違いが無いのにReadiness Probeが落ちているという問題設定から、「トラブルを解決し、PodがReadyであることを証明しろ!」という意味を込めてつけました。
Readiness Probeとの語呂合わせも良く、自分でも気に入っている問題名です。
なお、ルーターの設定が永続化されておらず、再起動試験を突破できなかったチームが2チームありました (うち1チームは後から気付き、再提出で無事正解)。
再起動については終了条件にかなり明確に書いたつもりです。次回に活かして欲しいですね。
別解について
かなり別解の多い問題となってしまったなぁと思っています。作問者として、BGPの柔軟さを再確認しました。
制約の設定にかなりこだわって解法の大筋までは絞れたのですが、細かい別解まで制約で絞ろうとすると大きなヒントになってしまうというジレンマがあり、ある程度は別解を許容する形になりました。
想定解法として用意したのは「まともなネットワークオペレーターならこうするだろう」という方法です。
実際、あらゆる解法の中で1番綺麗な経路情報が広報される方法かと思います。解説で記した別解を使うと、ルーターに対して全く同じ経路情報がいくつも追加されたり、果てにはアンダーレイネットワークの経路も増幅されてしまうなど、あまり綺麗な状態にはなりません。
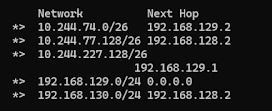
想定解においてrouter-1に広報される経路 ↓
最も重複経路が多かった解の場合 ↓
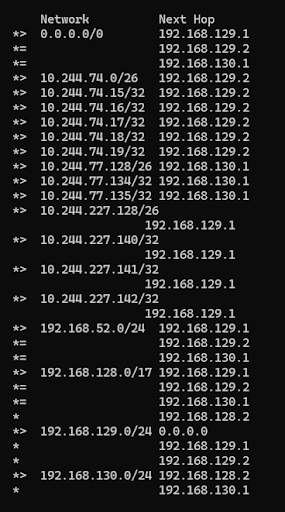
終了後に競技者に聞いてみた所感として、どうやらLLMに丸投げしたチームの多くが、根本原因であるNode to Nodeメッシュの無効化に行きつかず、重複広報に場当たり的な対処をする解法になったみたいです。
LLMが出してきた暫定対処で満足するのではなく、ぜひ「お前それネットワークオペレーターの前でも同じこと言えんの?」という観点で回答と向き合って欲しかったなと思います。
余談: Kubernetesのネットワーク
実際にL2セグメントが分かれたノードをKubernetesクラスタにしたいときは、(今回の問題では封じた解法ですが) 素直にOverlayモードに切り替えるのが一番適切かつ手っ取り早いと思います。
オーバーレイネットワークであれば、L3疎通さえ通っていればノード間通信が可能になります。
ただ、今回の解法のようにアンダーレイのネットワーク機器に対してPod CIDRを広報する方法には、オーバーレイネットワークよりもオーバーヘッドが少なかったり、ネットワーク機器の機能を活かせたりといったメリットがあります。
実際にAWSやGoogle Cloud、AzureといったメジャーなクラウドプロバイダーのKaaSはアンダーレイネットワークとの連携を強固にとっており、AWSに至ってはVPC内のIPアドレスを直接Podに割り当てることでPodとVMが直接疎通できるようにしていたりします。
国内ですと、CybozuさんのNeco基盤はCNIがアンダーレイネットワークに対して広報する方式を採用しているようです。
Kubernetesのネットワーク、掘り下げれば掘り下げるほど面白いので、興味を持った方はぜひ色々調べてみてください!